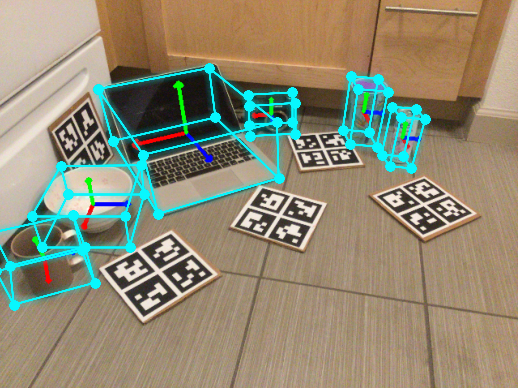
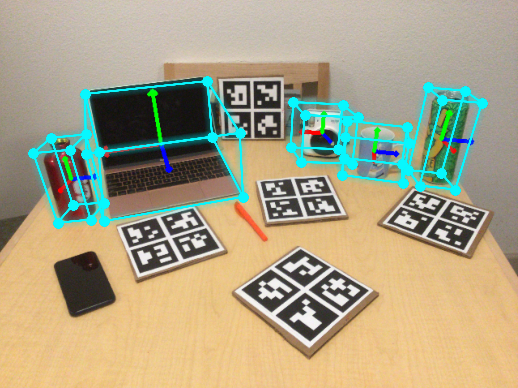
Our method studies the complex task of holistic object-centric 3D understanding from a single RGB-D
observation. As it is an ill-posed problem, existing methods suffer from low performance for both 3D
shape and 6D pose estimation in complex multi-object scenarios with occlusions. We present ShAPO, a
method for joint multi-object detection, 3D textured reconstruction, 6D object pose and size estimation.
Key to ShAPO is a single-shot pipeline to regress shape, appearance and
pose latent codes along with the masks of each object instance, which
is then further refined in a sparse-to-dense fashion. A novel disentangled
shape and appearance code is first learned to embed objects in their
respective shape and appearance space. We also propose a novel, octree-
based differentiable optimization step, allowing us to further improve
object shape, pose and appearance simultaneously under the learned latent space, in an
analysis-by-synthesis fashion. Our novel joint implicit
textured object representation allows us to accurately identify and recon-
struct novel unseen objects without having access to their 3D meshes.
Through extensive experiments, we show that our method, trained on
simulated indoor scenes, accurately regresses the shape, appearance and
pose of novel objects in the real-world with minimal fine-tuning.
Our method significantly out-performs all baselines on the NOCS dataset with
an 8% absolute improvement in mAP for 6D pose estimation.