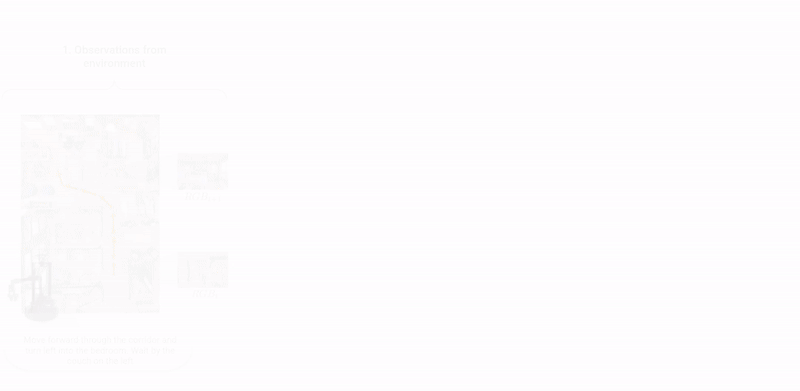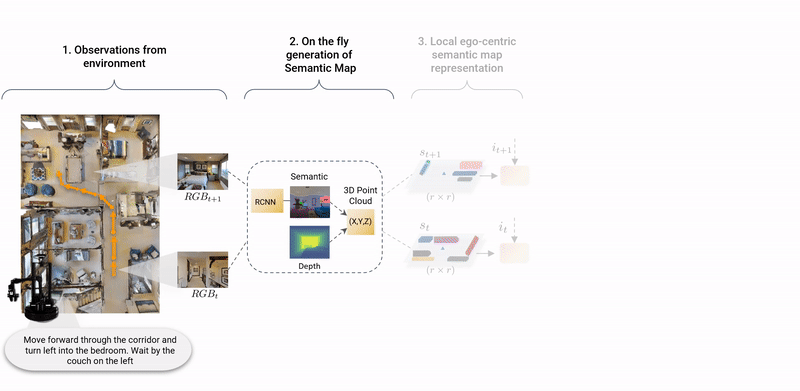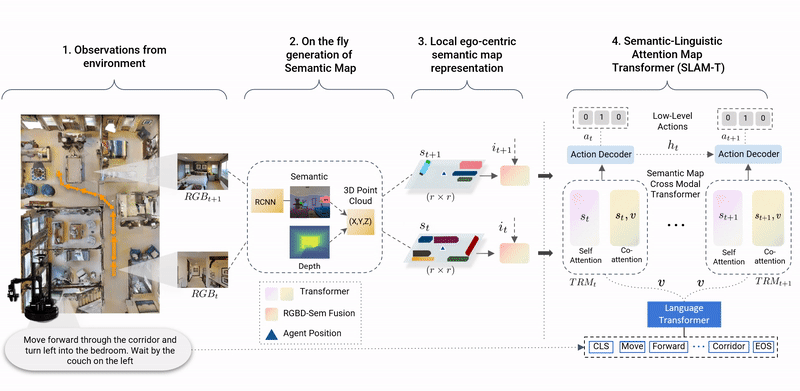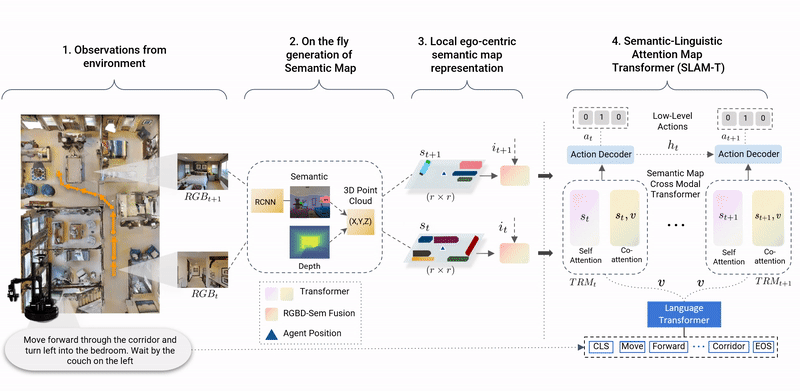
This paper presents a novel approach for the Vision-and-Language Navigation (VLN) task in continuous 3D environments, which requires an autonomous agent to follow natural language instructions in unseen environments. Existing end-to-end learning-based VLN methods struggle at this task as they focus mostly on utilizing raw visual observations and lack the semantic spatio-temporal reasoning capabilities which is crucial in generalizing to new environments. In this regard, we present a hybrid transformer-recurrence model which focuses on combining classical semantic mapping techniques with a learning-based method. Our method creates a temporal semantic memory by building a top-down local ego-centric semantic map and performs cross-modal grounding to align map and language modalities to enable effective learning of VLN policy. Empirical results in a photo-realistic long-horizon simulation environment show that the proposed approach outperforms a variety of state-of-the-art methods and baselines with over 22% relative improvement in SPL in prior unseen environments.
SASRA is a multi-modal method to combine classical semantic mapping techniques with a learning-based approach for the task of Vision-and-Language Navigation in Continuous Environments.

SASRA agent builds a top-down spatial memory in the form of semantic map and aligns the language and map features to complete the long-horizon navigation task in 37 and 62 steps
SASRA performs effective instruction-guided navigation in unseen real-world environments.
@INPROCEEDINGS{irshad2022sasra,
author={Irshad, Muhammad Zubair and Chowdhury Mithun, Niluthpol and Seymour, Zachary and Chiu, Han-Pang and Samarasekera, Supun and Kumar, Rakesh},
booktitle={2022 26th International Conference on Pattern Recognition (ICPR)},
title={Semantically-aware Spatio-temporal Reasoning Agent for Vision-and-Language Navigation in Continuous Environments},
year={2022},
volume={},
number={},
pages={4065-4071},
keywords={Visualization;Three-dimensional displays;Navigation;Semantics;Natural languages;Transformers;Feature extraction},
doi={10.1109/ICPR56361.2022.9956561}}